技術ブログ
2013年6月19日(水)
調査票のいらない調査「Scanamind(スキャナマインド)」Vol.4
Scanamindのデータ処理技術
この調査手法について解説する、調査票のいらない調査「Scanamind」シリーズ第4回は、Scanamindのデータ処理技術についてレポートいたします。
記事INDEX
今回は、次の2点について解説したいと思います。
1:Scanamindのデータ処理ロジックを説明し、アウトプットが生成される過程を示す。
2:Scanamindが採用している量子数理体系(*1)は、マーケティングリサーチで一般的に使用される統計数理とどのような点が最も異なるのかを明らかにする。
(*1)電子や原子核といった微視的スケールでの物理現象を扱う量子力学を記述するための数学体系。
Scanamind におけるデータ処理の最終目的は、調査対象者から挙げられたすべての概念を位置関係(座標)の形で可視化することにあります。調査対象者より与えられた関係の強弱が強ければ近くに、弱ければ遠くになるように配置され、データが可視化されます。
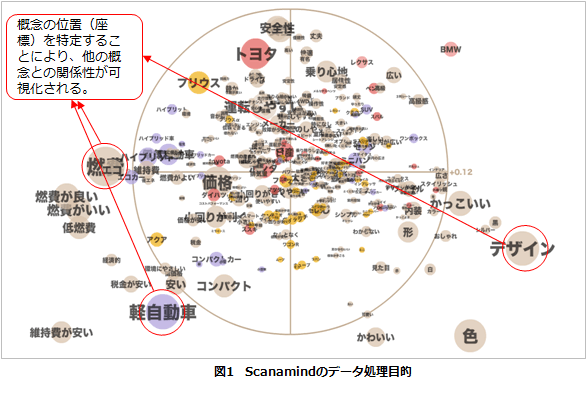
Scanamindのインプットデータとアウトプットデータの特徴は以下になります。
【1】インプットデータ
(1)調査対象者は、自ら挙げた概念12個について、組み合わせた2個の関係が強いか弱いか、4段階の評価を与えます。
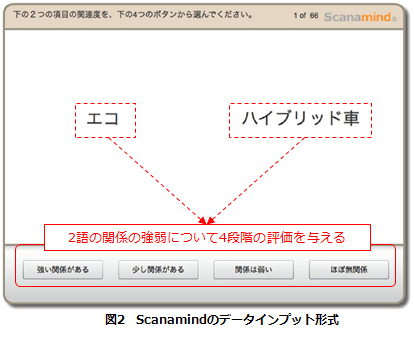
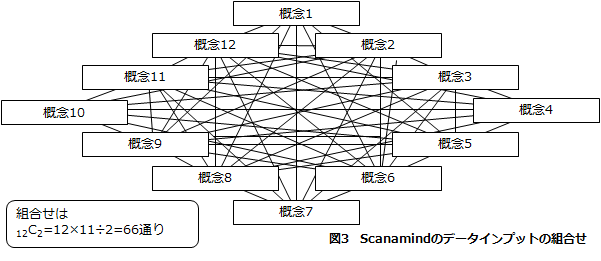
(2)調査対象者は12個の概念すべての組み合わせ66通りの評価を、(1)のように4段階で与えます。これにより、調査対象者が意識せずとも、12個の概念すべてについて、他の概念との関係において相対的評価を与えることになります。
この作業の結果、調査対象者一人一人について、それぞれ以下のような概念の関係が明らかになり、調査対象者が1000人いれば、1000人分の概念の関係が明らかになります。
【2】アウトプットデータ
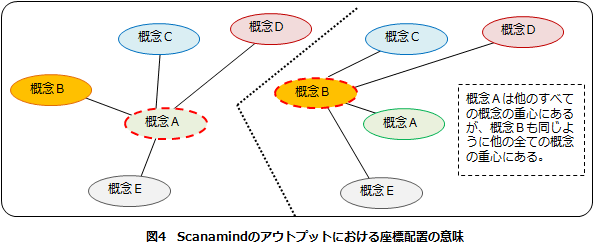
Scanamindにおける概念のマッピングは、調査対象者全体において、ある概念が他の概念すべての重心に来るように配置されます。図4において、概念Aは4段階評価によるウェイトを与えられた際、他の概念B、C、D、Eの重心に配置されますが、概念Bからみると他の概念A、C、D、Eの重心になるように配置され、同じようなことが概念C、D、Eにも当てはまります。
このようにScanamindのアウトプットでは、すべての概念は他のすべての概念の重心に位置します。これらが可能になるのは、データインプット時に全概念の全組み合わせについて相対的評価を行っているからです。
こうしたアウトプットデータを解釈する上でのヒントを、以下に紹介します。
【アウトプットデータの解釈1】 ~中央に位置する概念~
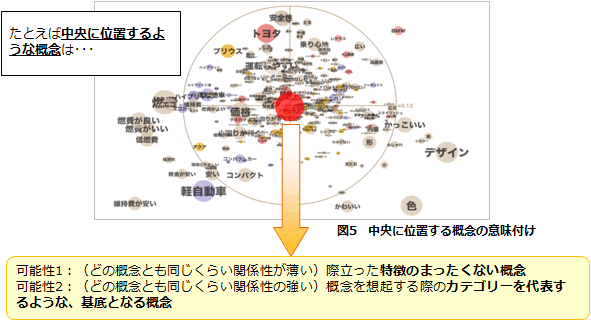
【アウトプットデータの解釈2】~似通った概念を統合しない理由~
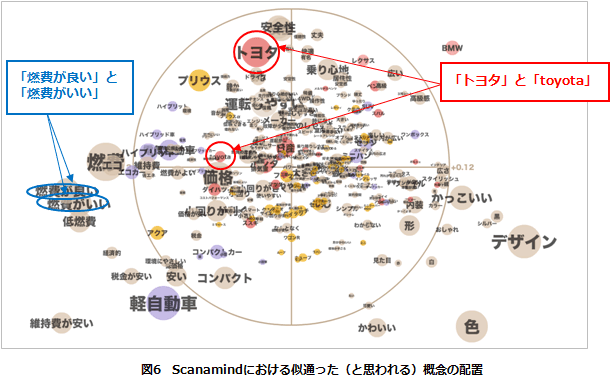
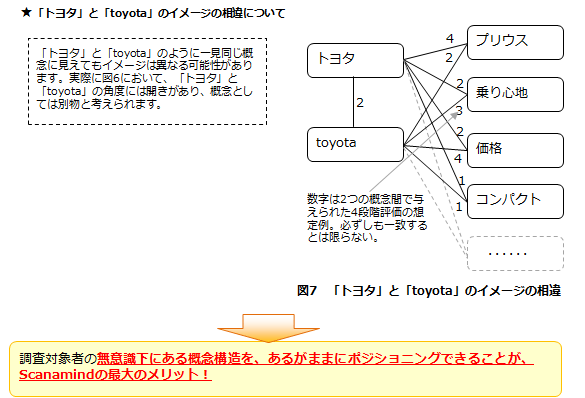
Scanamindでは、事前にリサーチャーが意図的に統合しなくても、「燃費が良い」「燃費がいい」のような似通った4段階評価を与えられた概念どうしは自然と近い座標にプロットされます。逆に「トヨタ」「toyota」は若干開いた角度にプロットされるため、調査対象者が「トヨタ」と「toyota」に抱いているイメージには違いがあることがわかるでしょう。もしこれを事前にリサーチャーが統合していたならば、このような事実は見過ごされ、結果は歪曲されていたはずです。
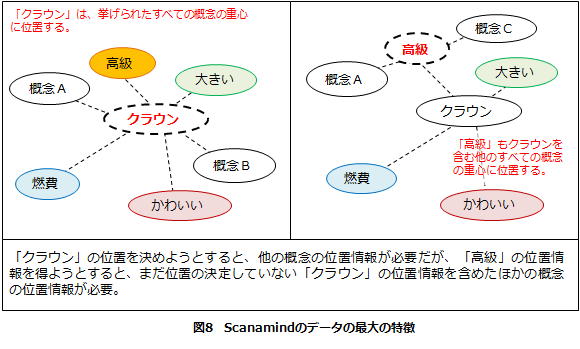
■Scanamindのデータの最大の特徴
Scanamindでは、12個すべての概念がそれぞれ何らかの関係性を持ちます。たとえば図8のように、「クラウン」は他のすべての概念の重心に位置しますが、「高級」も「クラウン」を含む他のすべての概念の重心に位置します。それら以外の概念も同様です。
■Scanamindにおけるデータ処理の問題点
Scanamindでは、ある概念の位置は他のすべての概念の重心に位置します。そのため、ある概念の位置を決定した上で、演繹的に他の概念の位置を求めるという統計数理的なアプローチが利用できません。他のすべての概念の位置が確定していないため、どの概念からスタートしても位置を確定することができないのです。
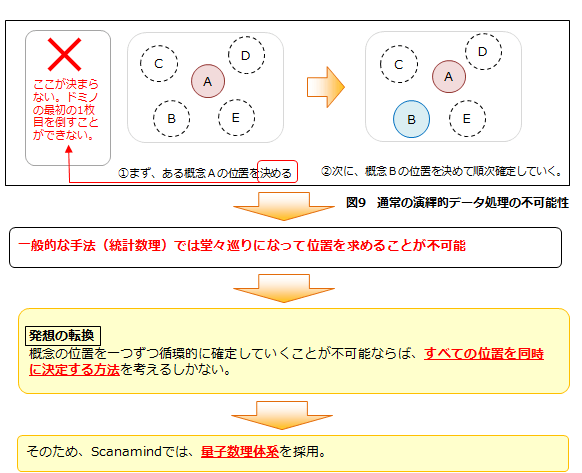
【1】量子数理体系だと、なぜ解決できるのか?
量子力学とは原子より小さい微小スケールの物理現象を扱うための学問体系です。そして、原子より小さい世界では、因果関係が成立しないことがわかっています。
たとえば私たちの日常生活において、移動しているビリヤードの玉の位置と速度を観測すれば、数秒後の位置を正確に予測することができます。しかし、同じように原子内の電子の位置と速度を観測しても、電子は観測するための光が当たっただけで影響を受け、容易にその位置や速度を変えてしまうため、観測後の位置は確率的にこの辺りだと推定するしかありません。微小スケールの世界では、「現在の状態からそれ以降の状態を予測できる」という古典力学の因果律(*2)が成立しない世界なのです。
このように、目に見えず、因果関係が成立しないという点は、マーケティングリサーチにおける「ブランドイメージ」「購入意向」といった概念においても共通しているため、Scanamindのデータ処理ロジックとして、量子数理体系の親和性があると考えられています。
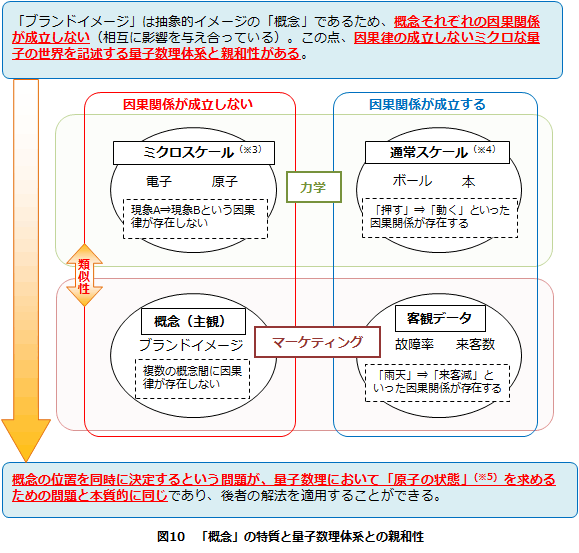
(*3)ここでの「ミクロスケール」は原子レベルのごく微小なスケールを示す。
(*4)ここでの「通常スケール」は原子レベルから見てマクロなスケールを示す。
(*5)記述された原子の状態を「波動関数」という関数で表現するが、波動関数を求めるための方程式を「波動方程式」と呼び、これは線形代数における固有方程式と同じ形式になる。
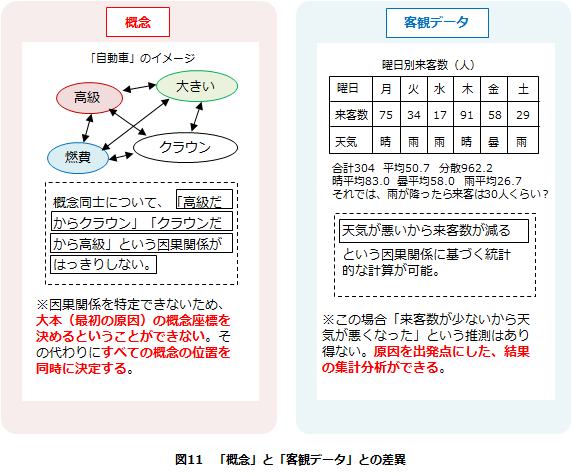
【2】「概念」と「客観データ」との差異について
次の図11にある天気と来店数の関係のような「客観データ」は、データ間の本質的な因果関係に基づいた集計・分析が可能です。しかし、Scanamindが分析対象としているブランドイメージなどの「概念」は相互の因果関係では説明できないため、原因から出発して演繹的に集計・分析を進めることができません。そのため、すべての概念の位置を同時に決定する必要があるのです。
Scanamindのデータ処理手順は、調査対象者の全回答データをすべてシステムに投入し、適当に仮設定したすべての概念の座標を、何回も何回も繰り返し検算させるイメージになります。
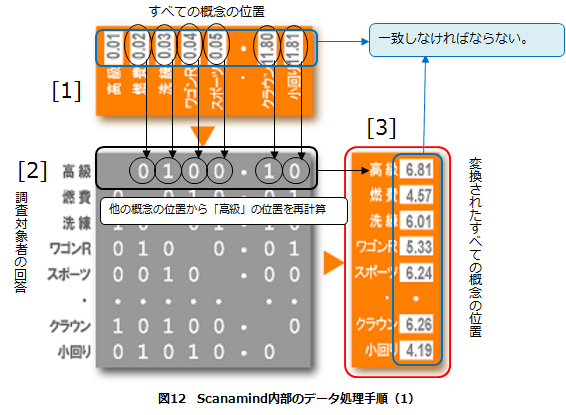
(1)すべての概念の位置を適当に仮設定
ここでは例として、0.1刻みで入力したことを示した。(図12 [1])
(2)調査対象者の回答を行列にして、すべての概念の位置を変換させる
Scanamindでは、調査対象者に対して概念どうしの関係性を4段階で評価させるが、ここでは表記を簡略化して「1=関係あり」「0=関係なし」として示した。(図12 [2])
(3)すべての概念の位置を計算
この例では「高級0.01 ⇒ 6.81」、「燃費0.02 ⇒ 4.57」…となり、最初に仮設定した結果と異なってしまうため、変換させた「調査対象者の回答」が誤っていることになってしまう。しかし、「調査対象者の回答」が正しいことを前提に、すべての概念の位置を決定したので、この場合は最初に仮設定したすべての概念の位置が誤っていたことになる。(図12 [3])
(4)何万回、何百万回と一致するまで再入力して検算を行う
すべての概念の位置を、他の数字で新たに設定し直し、再度変換結果を出力し、元の仮設定した座標と一致しているかどうかを検算する。異なっていれば再度・・・と何万回、何百万回と一致するまで再入力を続ける。(図12 [1]→[2]→[3]の繰り返し)
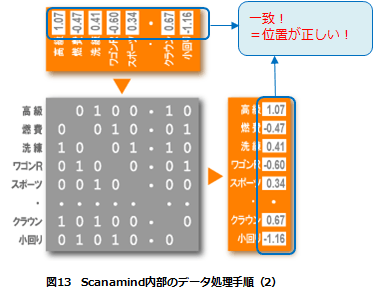
(5)完全に一致
何百万回と計算を続けるうちに、仮設定したすべての概念の位置と、変換されたすべての概念の位置が完全に一致する(図13)。
一致したということは「調査対象者」の回答が正しいと認識できているという意味であり、ひいては、仮設定したすべての概念の位置が正しい位置にあるということを示す。
(6)座標上にプロット
すべての概念の位置が正しいことがわかったため、データを保存し、座標上にプロットを行う。
米国・ドイツ・フランス・英国でも同社の特許権が成立しています。
x ※「Scanamind」は株式会社クリエイティブ・ブレインズの登録商標です(登録番号第5109952号)。また世界主要35カ国における同社の登録商標です(国際登録第1131308号)。
※「Scanamind」公式サイトhttp://www.scanamind.jp/
次回は、GMOリサーチで実際に行ったScanamind自主研究レポートを紹介する予定です。
「Scanamind」についての詳細お問い合わせは以下まで。
GMOリサーチ株式会社 JMI事業本部 担当山田
Tel.03-5784-1100
[email protected]

GMOリサーチ
GMOリサーチ&AI株式会社
GMOリサーチは、先進的なネットリサーチで日本とアジアのマーケティングプロセスに新しい価値を提供する会社です。 自社メディア「infoQ」を含むアジアの13ヶ国・地域を繋いだアジア最大級のクラウド型消費者パネル「ASIA Cloud Panel」を保有。 調査会社・シンクタンク・コンサルティング企業など調査のプロに向け、ネットを活用した調査・集計・分析サービスと調査サンプルを柔軟に提供しています。

