技術ブログ
2011年11月2日(水)
ソーシャルメディア調査活用術 Vol.5
ソーシャルメディアを支える技術
最終回となった第5回は、こうしたソーシャルメディア調査を実施していく際に使用するさまざまな技術についてレポートいたします。
※ このレポートは、GMOジャパンマーケットインテリジェンス株式会社とGMOリサーチ株式会社の共同研究です。
記事INDEX
これまで、ソーシャルメディアから収集した口コミ情報をもとに、販売促進、商品開発、風評対策などに活用していく方法について述べてきましたが、今回のレポートでは、こうしたソーシャルメディアからテキストデータを収集する技術について解説します。
こうしたデータ収集手法には以下の2つがあります。
1:クローリング(crawling=這う)
ソーシャルメディア上に書き込まれたテキストデータを、情報の量や質に関わらずすべて収集する手法です。
2:スクレイピング(scraping=こする)
売れ筋ベストなどを紹介しているサイトのように、XMLなどのマークアップ言語で記述されたウェブページから、必要なテキストデータのみをタグで指定して回収する手法です。
上記のうち、ソーシャルメディア調査で、Twitterやブログから情報を収集する際によく使用されるのは広範囲の口コミ情報を収集できる前者のクローリングになります。
次にクローリングの際に主として用いられている3つのアプローチを紹介します。
『1. 一般的なクローリング』は、例えばグーグルの検索ロボットがウェブ上を巡回し、情報を収集するようなイメージです。もちろん、このアプローチだけでもクローリングは可能ですが、プログラミングの作成に手間がかかるため、もう少し効率的にできるようにしたのが『2. RSS・Atomフィードを用いたクローリング』『3. APIを用いたクローリング』です。
以下にこの3つのアプローチの詳細を紹介します。
1. 一般的なクローリング
PHPやPerlなどスクリプト系の簡易プログラミング言語を用いてクローリングプログラムを作成し、システムメモリ内に常駐させることで、事前に指定したタイミングになるとバッチが走り、更新されたテキストデータをデータベースに格納します。また、放流すると延々とリンクを追いかけるクローリングプログラムもあります。
2. RSS・Atomフィードを用いたクローリング
一般にブログはXMLという言語でコーディングされており、このXMLは構文定義に優れていることから、ブログの表題・URL・コメントの更新情報をRSS・Atomフィードという一覧表にまとめ、配信するサービスを国内のほとんどのブログプロバイダは実装しています。この場合のクローリング設計は、RSS・Atomフィードを取得できるプログラムを作成して、システムメモリ内に常駐させれば、事前に指定したタイミングになるとバッチが走り、ブログやサイトの更新情報を取得することができます。

※ フィード (Feed):ウェブサイト(特にブログやニュースサイトなど)のコンテンツの概要もしくはコンテンツ全体を配信用に加工した文書のこと。代表的なフォーマットとしてはRSSやAtomがあり、現在はこれらフィード機能を持つブログでは以下の統一アイコンが使用されるようになっています。
3. APIを用いたクローリング
ソーシャルメディアのプロバイダが外部に対してデータ交換するために提供しているAPI(Application Program Interface)というプログラムを利用して、定期的に当該ソーシャルメディアから新規データを取得する方法です。
例えば、TwitterやFacebookには、タイムライン(発言が流れてくるスペース)情報だけでなく、オープン領域のスクレイピングを行うAPIが提供されているため、検索対象データを容易に取得可能です。
クローリング設計としては、APIを利用したクローリングプログラムを作成。Streaming API(TwitterではFirehose)の場合は自動的に更新データが送られてくるので、それらのデータを正規化した上でデータベースに格納します。
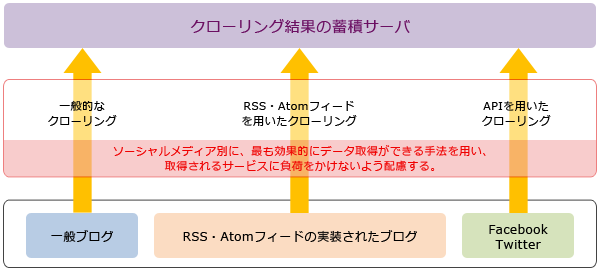
ちなみに、こうしたクローリング作業は、インターネット全体に負荷をかけないよう配慮することが必要だと言われています。クローリングが頻繁な場合はデータ蓄積サーバだけでなく、クローリングを行う相手方のサーバや、取得したデータが流れるインターネットのシステム全体に大きな負荷をかけることになるため、技術的に最も負荷の軽い収集アプローチを選択します。
取得したテキストデータの中でも、特にデータ構造がサービスプロバイダごとに異なるブログでは、データベースに格納できる形式に整形しなければなりません。
具体的には、「タグを取り除く」「データベースの当該フィールドに合致する適切なデータを抜き出す」といった工程を、サービスプロバイダのフォーマット別に実施する必要があります。
そうやって正規化されたデータはサーバ上にデータベースとして格納し、CSVなどのフォーマットでローカルにダウンロードし、ローデータとして調査分析に用います。

(1)ステータスID :各ツイートにふられた固有のID
(2)ツイート本文 :ツイートされた本文
(3)Twitter ID :発言者ID
(4)ユーザー名 :発言者ユーザー名
(5)プロフィール :発言者プロフィール
(6)フォロー数 :フォローしているユーザー数
(7)フォロワー数 :フォローされているユーザー数
(8)発言日時 :発言日時(秒単位)
(9)ステータスURL :ステータスIDの固有URL
GMOリサーチでは、こうしたソーシャルメディア調査におけるクローリング業務を、多言語対応も含めて効率的に実行できる新サービスGSR(Global Social Research)をリリースしました。 このGSRの主な特徴を2点紹介します。
●多言語対応
10ヶ国語(英語・日本語・フランス語・ドイツ語・ロシア語・スペイン語・ポルトガル語・アラビア語・韓国語・中国語)にわたる各国のブログ・Twitter・Facebookに対応し、これらの言語でソーシャルメディアリサーチを行うことができます。
●言語に依存しない発言意図の分類が可能
GSRは、MFA(Mind Factor Analyzer)と呼ばれる解析システムを採用しており、通常のクローリングエンジンで採用している構文解析(文章を品詞ごとに分解して、その中にあるキーとなる言葉を抽出し、辞書と照らし合わせて文章の意味を判断)を行っていません。MFAでは、最初に人間が与えたトレーニングセットの文に従って行った判断を数値化し、その結果と他要素(語の位置・使われ方・語と語の距離など)を比較する計算型解析を行います。そのため、言語に依存しない発言意図の分類(因子分類)が可能となり、ソーシャルメディア上に存在する膨大なデータを自動で分析することができます。
※MFAはONTROX社のトレードマークです。
→ GSRの詳細はこちら:http://www.gmo-research.jp/service/gsr.html
全5回にわたり、ソーシャルメディア調査活用術を述べてきましたが、最後に総括したいと思います。 海外では、比較的早い時期からソーシャルメディア調査に対する関心が高まっていましたが、国内では、実際の調査プロジェクトに応用されることはあまり多くなく、手法に対する有効性の判断も海外と国内ではかなりの開きがありました。
しかしながら、最近になって日本企業のマーケッターの人たちから、ソーシャルメディア調査の話題が聞かれるようになりました。
第3回でお話したように、ソーシャルメディアを活用したマーケティングリサーチは、「アスキング」から「リスニング」へと調査のアプローチが変わります。「リスニング」に調査のアプローチがシフトすると、ソーシャルメディアに書き込まれた膨大なデータの中から何を収集し、収集したものをどのように理解すればよいのかが非常に重要なポイントになります。ソーシャルメディアの活用で、マーケッターやリサーチャーがどのようなコンシューマー・インサイトを見出すことができるか、今まで以上に腕の見せどころが増えると考えています。
次回からは、新シリーズとして顧客満足度調査に関するレポートを予定しています。

GMOリサーチ
GMOリサーチ&AI株式会社
GMOリサーチは、先進的なネットリサーチで日本とアジアのマーケティングプロセスに新しい価値を提供する会社です。 自社メディア「infoQ」を含むアジアの13ヶ国・地域を繋いだアジア最大級のクラウド型消費者パネル「ASIA Cloud Panel」を保有。 調査会社・シンクタンク・コンサルティング企業など調査のプロに向け、ネットを活用した調査・集計・分析サービスと調査サンプルを柔軟に提供しています。

